QC clustering
The quality of the data can also be inferred from gene expression profiles represented via dimension reduction methods. Suitable methods in Panhunter are PCA, t-SNE and UMAP. The ‘New Comparisons’ app should be used in the following.
Clustering by sex
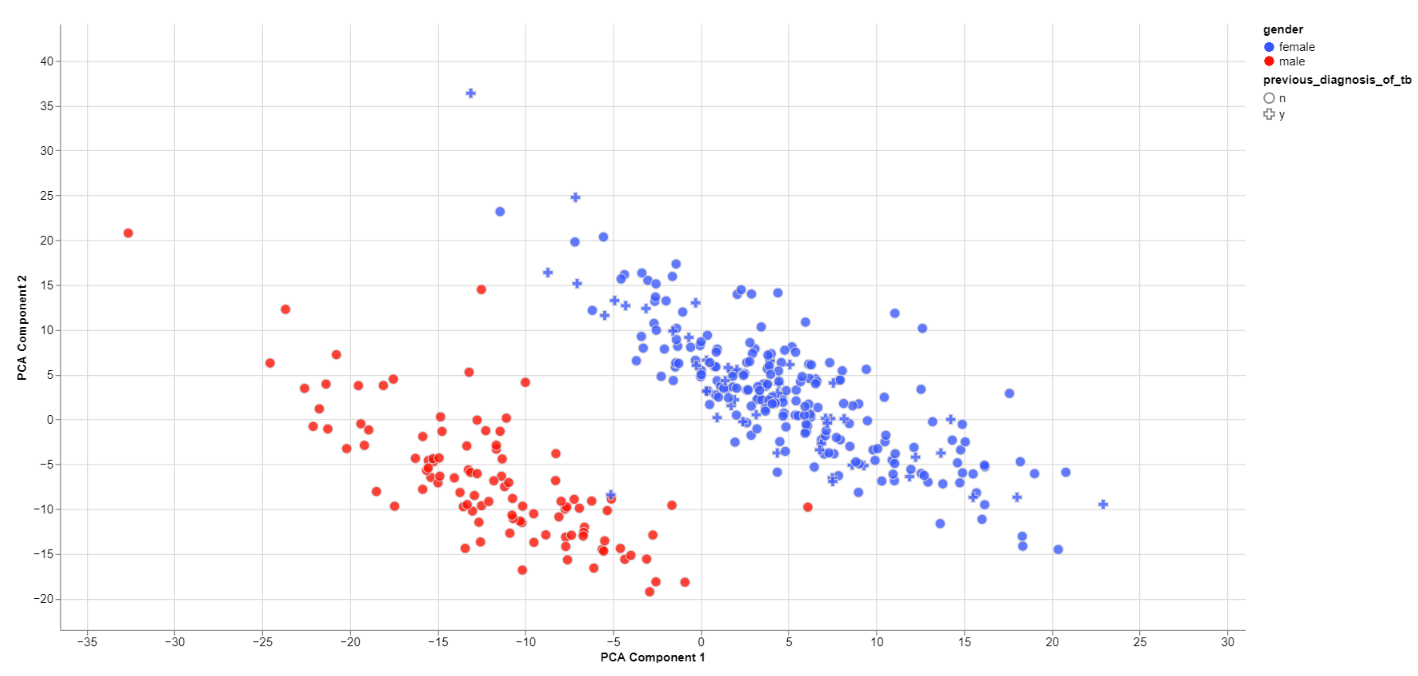
The biological sex should always be one of the greatest disparities between data points because an entire chromosome is different. Thus, there may be reason to exclude samples that are truly different from the rest of their group. However, some studies list gender which should not be confused with the biological sex.
What can also be inferred from the plot is that, in this data set, only females have been diagonsed with tuberculosis before, leading to a dependence between gender and previous_diagnosis_of_tb. These relationships are very important because correlation explained by the previous diagnosis can in some cases be completely explained by the gender/sex association.
PCA features
The categorical and numerical variables that are responsible for the variance in the data can be calculated with the buttons shown below in the picture.
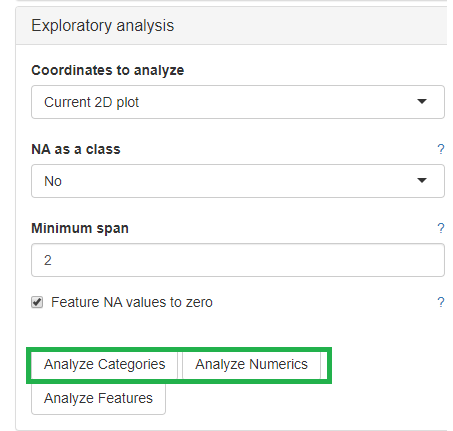
⚠️ Keep in mind that the default is to analyze only the current 2D plot of the dimensional reduction and may vary even by method (PCA,t-SNE, UMAP).
Check outliers
Even when there is no gender/sex variable present, there might be clear clustering. When comparing two groups, one can use the check outliers tab after selecting the groups, to look at up and downregulated genes and infer information from the results.
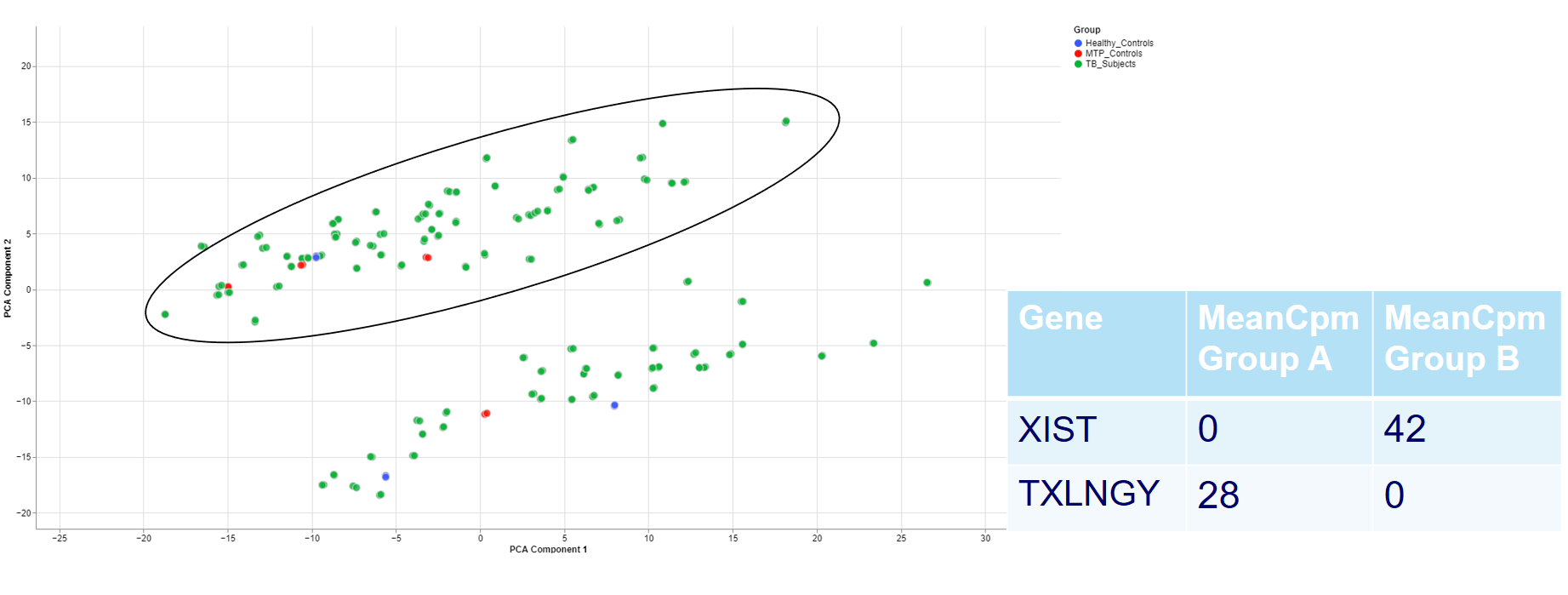
For example, the two groups are clustering completely different in the PCA plot. Even when there is no labeling variable, the comparison shows that certain genes are more present in the groups. Because the presented genes belong to the inactive X chromosome and the Y chromosome, we can infer that there are males and females in the data.
This is important for quality control because of the large influence of the biological sex which might otherwise be neglected.
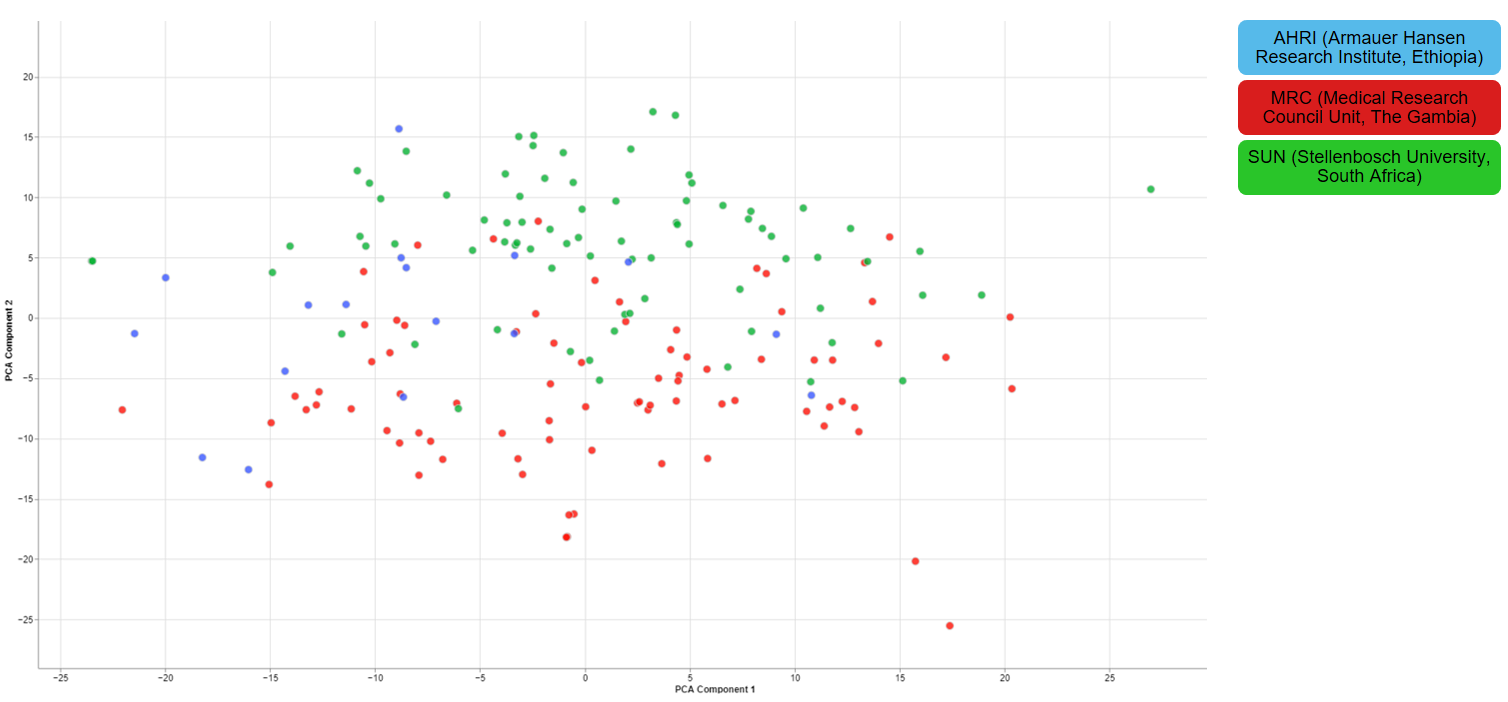
Clustering of other features
For one of the studies, different sites were used to collect blood samples from participants. This inevitable lead to differences that have to be accounted for and are thus important for the quality of the data.